
0.2 Systemic Safety Hello World
Searching for nasty surprises in an AI system
This post goes through some work I did to probe for unexpected failure modes in an AI system. It results from a rough, first run-through of my Generating Process (my series of steps for constructing a research agenda) made during its original development. I count this as iteration 0, and consider it a kind of practice run I will not be writing up in full. Unfortunately, I under-estimated the amount of compute I would need to complete my experiment, so it remains unfinished1. While this was disappointing, it was nevertheless a good learning exercise.
AI and complex systems
Complex systems are marked by a multitude of interacting parts. They are often adaptive, nonlinear, and chaotic, and it can be difficult to usefully draw boundaries between sub-components. Complex systems are the default in nature2. This is easy to forget for the modern, systematically trained individual. We are used to studying and thinking about complicated systems: ones you can take apart and put back together, and where you can say precisely what the action of the system will be. Complex systems are not like this. Take the weather for example: for all the research and computing power thrown at making weather forecasts, they are still noticeably unreliable.
Systems that are merely complicated though, like cars, are much easier to predict. If your car journey takes longer than expected, it’s usually because of the complex part of car travel (bad traffic) rather than because of the complicated part (the car broke down)3. The remarkable success of modern science has largely been about reducing the complex to the complicated. As Roberto Poli puts it, “Science is for the most part a set of techniques for closing open systems in order to scrutinize them”. Running an experiment or calculating the dynamics of a system first involves isolating it from as much of the world as possible – you want to minimise the number and degree of interactions4. Then, when you have learned how the closed system behaves, you can try to use it as a predictable building block in some larger machine.
Complexity is relevant in two different ways for AI. First, modern AIs like LLMs are themselves complex systems, which is downstream of the fact they are trying to model a complex world. To quote Richard Sutton’s Bitter Lesson5:
“[The] actual contents of minds are tremendously, irredeemably complex; we should stop trying to find simple ways to think about the contents of minds, such as simple ways to think about space, objects, multiple agents, or symmetries. All these are part of the arbitrary, intrinsically-complex, outside world. They are not what should be built in, as their complexity is endless; instead we should build in only the meta-methods that can find and capture this arbitrary complexity.”
LLMs are enormous neural networks with many sub-components, including learned sub-networks and features, all interacting with each other while driven by arbitrary inputs. They are grown, organic, messy things – not precisely engineered machines. Their behaviour will never be truly predictable; and it is likely, given the performance advantages of building AI this way, that this isn’t going to change any time soon.
But there is also a second source of complexity: that of the larger system containing all the AIs, humans, and machines that make up society. This system will have its own dynamics, its own idiosyncracies, and its own failure modes. For many people, the canonical example of a complex system failure was the 2007-8 finanical crisis. The global financial system seemed to be doing great, until a failure in one part of it, the US housing market, set off a chain reaction all over the world. It wasn’t just that some banks outside the US failed, or that some countries had debt crises. It permanently changed the global economy to such an extent that, in places, productivity growth has barely recovered nearly twenty years later. Famously, Goldman Sachs CFO David Viniar declared that during part of the crisis they were “seeing things that were 25-standard deviation moves, several days in a row.”6 Goldman were treating part of the finanical system as a closed, complicated system. Their models worked great in ‘normal’ times. 25-sigma events shouldn’t occur in the lifetime of the universe, let alone several days in a row. It became popular to describe the crisis as a ‘black swan’ – an ‘unknown unknown’ that came out of the blue.
As AI deployment throughout the economy gathers pace, our exposure to these kind of problems may increase. The world will be even more complex and incomprehensible than it was before. Even if we do a good job setting up regulations and controls, and we train models that appear well aligned to our goals, this happy equilibrium will not last. Whether because of a step change (e.g. in AI capabilities) or because of a series of small changes that gradually reach a tipping point, ‘normal’ times will end and the system will fail7. And we will find ourselves with highly powerful and no-longer-quite-aligned AIs deployed everywhere.
Of these two scales of complexity, intrinsic to the AI and extrinsic in the wider world, I feel the latter is the more neglected topic. As I worked through the early steps of my process, defining a successful future and how we might get there, the big thing that jumped out to me was just how comprehensive a solution will need to be. Every aspect of society will be touched by and engaged with AI. This shouldn’t be surprising. Humans already live in complex societies where many aspects are regulated and formalised. We aren’t illiterate hunter-gatherers anymore. The processes we will need to govern and live with AI will be the dominant processes that run our lives.
This is a fiendishly difficult problem to do anything about. You can’t simulate the whole world and check if everything is going to work out. But if it is a real problem, we need some kind of approach to anticipate these dangers.
Minimum Viable Experiment
As I first worked through my Generating Process, I sketched out a Theoretical Solution to AI risk. At this stage, my project was rather fresh, so you should read this as a basic, high-level overview of my thinking. A short summary is:
Given beyond-human-level AI will impact all aspects of the world, it will be part of a complex adaptive system. Any alignment ‘solution’ will likely be an ongoing process similarly large in scope (as opposed to one, neat provable technique), and we must work to make this system as bounded and predictable as possible. This alignment process will involve at least the following integrated sub-processes: goal-setting, technical alignment, monitoring, and governance, and work towards it will need to take interactions between them into account by design.
The next step was to think of a Minimum Viable Experiment. That is, what assumptions in this proposed solution would be most useful to test? I identified that the key point running through my thinking, and distinguishing my approach from the mainstream of AI safety research, was its systemic emphasis. By my world model, we should expect, by default, the following in systems containing capable AI:
Strange, unexpected behaviour under conditions you didn’t even think to plan for (‘unknown unknowns’).
Failures of alignment when the system undergoes changes, perhaps because of a perturbation or because of drift.
I wanted to test these assumptions by setting up an experiment where I might observe this kind of behaviour. The system would need to be complex enough to be nontrivial, but simple enough to actually build. Along the way I would learn a few things:
How to set up experiments on simple AI systems.
What kinds of weird behaviour you can get out of interacting LLMs.
How to model perturbations to AI systems.
How to measure drift in AI systems.
Broadly, how effective a method of analysis my approach is.
Unfortunately, I had naive expectations about the amount of compute I would need to run a nontrivial system. Because of this, I only made progress on the first point. The rest of this post will give an overview of what I attempted.
Systemic Safety Hello World
As a minimal implementation of my ideas, I decided to call my experiment Systemic Safety Hello World8. The code can be found on GitHub, here. The idea was to construct a system of interacting components and then sweep through various parameters to identify phases of behaviour. I would classify these phases as good or bad, and surprising or unsurprising. By discovering bad ‘unknown unknown’ phases – negative patterns of behaviour I did not expect in advance – this would function as a way of measuring complex system failures. It was not meant as comprehensive solution to AI risk, but as the opening move in the development of a kind of complex system evaluation, or ‘systemic eval’ (hence ‘Hello World’).
The experiment was centred around a Worker AI which, as the easiest-to-implement use-case, was a chatbot designed to respond to user queries in a helpful and harmless manner9. Helpfulness and harmlessness are somewhat contradictory values for a chatbot: if a user asks for help building a bomb, it would be unhelpful to refuse but harmful to comply. In practice, this means that if the model is failing on one metric, fixing this with more training may cause problems with the other. You need to find some middle ground where the model doesn’t simply refuse all requests out of caution, but still knows to refuse the worst ones.
The Worker was embedded in a small system consisting of a User, an Overseer, an Outside Expert, and a Teacher. The Outside Expert was also an LLM, whereas the others were generic bits of code (I wanted to make the User an LLM too but didn’t get that far). The operation of the system was intended to be as follows:
The User sends a query to the Worker
The Worker responds to the query
The Overseer periodically (e.g. every 5 interactions) intercepts the response and sends it to two Outside Experts
The Outside Experts rate the response for helpfulness and harmlessness and send the ratings back to the Overseer
The Overseer checks if either rating is above a re-training threshold, and then:
If the ratings are high enough, the Overseer does nothing and we return to step 1
If either rating is at or below the threshold, the Worker is sent to the Teacher for re-training in that domain, after which we return to step 1
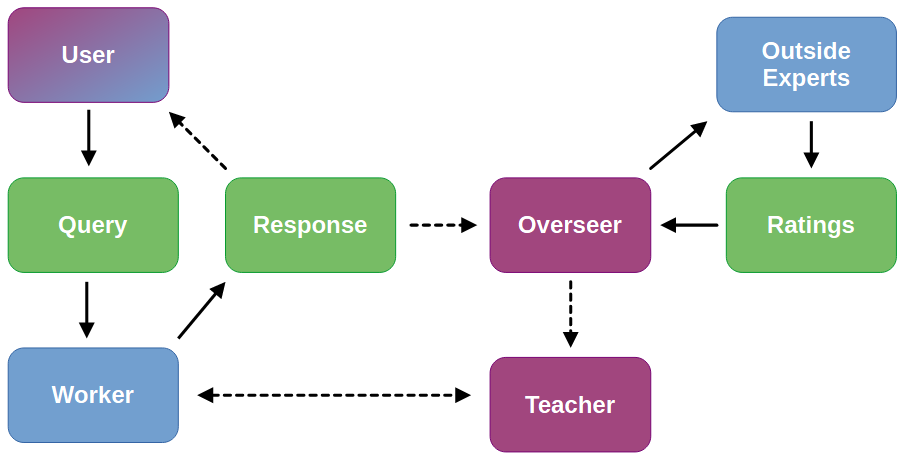
Going into a little more detail about each part:
Worker: Fine-tuned Mistral-7B-v0.110 that responds to User queries. Has a simple system prompt asking it to try and be helpful and harmless, and is given examples.
User: Class sending random queries to the Worker, sampled from the harmlessness test set. I wanted to make this an LLM, but didn’t get that far.
Overseer: Class that intercepts Worker responses and sends them to two Outside Experts for rating. Once the ratings have been produced, it checks them and returns if they are at or below the retraining threshold.
Outside Expert: Call to gpt-4 asking it to rate the Worker response for helpfulness or harmlessness.
Teacher: Class running fine-tuning (using DPO) on Worker when it has been sent for re-training on either helpfulness or harmlessness.
There were two other components I have not yet mentioned:
Instructor: Class that instruction-tunes the model used for the Worker, so that it is a capable enough chatbot to perform its role properly11. This was preferred to using an already instruction-tuned model, as the ones I tried seemed to have already learnt to refuse ‘harmful’ requests.
Perturbation: This was unimplemented, but the idea was to have another component that could disturb the system and see if it would knock it into some new phases of behaviour. The simplest way of doing this may actually have been to modify the User to make use of jailbreaking techniques.
My hypothesis was that this system would be just about complex enough to show nontrivial behaviour. By sweeping through parameters and observing the average ratings, the differences between the two rating types, and the frequency of re-training, I could classify the behaviour into various phases, distinguished by whether the system was behaving well and whether its behaviour was surprising. The parameters I could have tuned included:
Frequency of Overseer checks
Helpfulness and harmlessness rating thresholds
Different system prompts
Adversarial-ness of the User
Temperature of Worker
Number of samples used in each re-training run
If it turned out that the system was not complex enough to have surprising behaviour, I could have increased the complexity by adding more components, like the Perturbation.
However, once I got everything set up, I found I could only do ~ 1 fine-tuning run a day with the machine I had, which meant I could not sweep through regimes fast enough to plot phases and explore the system properly.
What Was Learnt?
So what did I learn from doing all this? Here are a few points:
To produce a meaningful simulation of even simple dynamics requires a lot more compute than I have access to at this time. My future projects will need to take this into account.
It is difficult to know how well the type of analysis I attempted will scale, particularly without having finished it for this simple case. It is clearly not meant as a comprehensive solution to the problem of complex failure modes – it is more a first step at probing the issue – but without taking that step it is hard to know what the next one should be.
Working through the motivation for the experiment lent coherence to some disparate ideas I had about complexity, which will be useful going forwards.
I learnt a lot about building systems containing LLMs and doing various types of fine-tuning.
While it was clearly unsatisfying not to finish this experiment, I am seeing it as a useful building block for the future. The next step is to take what I learnt and work through my Process again.
If you have any feedback, please leave a comment. Or, if you wish to give it anonymously, fill out my feedback form. Thanks!
And our baby daughter arrived while I was at the sharp end, so I decided to wrap up rather than attempt a redesign.
The boundary between complex and complicated systems is somewhat porous, particularly as abstractions are leaky. If your car breaks down, it may be for some mysterious reason that takes a highly skilled mechanic a long time to debug, but it’s more likely just a common part failure.
And even then, often the rest of a calculation will be dominated by linearising your equations in order to make them tractable.
Richard Sutton, The Bitter Lesson
Dowd et al., How unlucky is 25-sigma?
There is a school of thought that if we align the AI correctly, then as it gains capabilities it will become competent enough to manage these kinds of complexity concerns. This is not something I agree with as it skips out the part where the AI gains these abilities, during which we will be exposed to these dangers. It also assumes there is not some other set of harder problems that the AI will start to dabble incompetently in once it has mastered the kind of things that challenge humans.
A note on the name ‘Systemic Safety’: the idea of ‘systemic’ AI impacts has gained a bit of traction recently, with the UK AI Safety Institute and Open Philanthropy both offering grants to work on it. They seem to use the word systemic to mean something along the lines of ‘the effect of AI in the wild’. My usage is targeted at the intrinsic dynamics of systems that include AI, which has plenty of cross-over with theirs, but is somewhat different in emphasis. If I think of a better word for my usage than systemic I will start using it instead.
I used the helpfulness and harmlessness data from Bai et al., Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, which can be found on GitHub here.
Downloaded from Hugging Face: mistralai/Mistral-7B-v0.1.
Using the databricks-dolly-15k dataset.